Testing BirdNET In-Built model with Singapore Birds

Overview
How well can a machine tell the difference between a myna and a munia? This article dives into that question using BirdNET — the open-source bird sound recognizer — tested on 30 of Singapore's most familiar feathered residents. The goal: to assess how accurately the default BirdNET model performs when given real-world recordings from Southeast Asia.
Setup and Progress
I began by cloning the BirdNET-Analyzer repository and building a Docker image locally. There were a few bumps — the Dockerfile needed path fixes — but it was soon up and running.
Show Dockerfile
FROM python:3.11
# Install FFmpeg
RUN apt-get update && apt-get install -y --no-install-recommends ffmpeg && rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy BirdNET code
COPY . .
# Install Python dependencies
RUN pip install --upgrade pip \
&& pip install .
# Set entrypoint
ENTRYPOINT ["python3", "-m", "birdnet_analyzer.analyze"]
Species Targeted for Evaluation
To make the experiment as relevant as possible, I used the 30 species selected for NParks' Garden Bird Watch — birds that the public is encouraged to identify in parks and green spaces. Of these, I gathered 10 high-quality recordings for 27 species.
List of the Birds are the following
- Common Myna (Acridotheres tristis)
- Large-billed Crow (Corvus macrorhynchos)
- Yellow-vented Bulbul (Pycnonotus goiavier)
- Asian Koel (Eudynamys scolopaceus)
- White-breasted Waterhen (Amaurornis phoenicurus)
- Asian Glossy Starling (Aplonis panayensis)
- Scarlet-backed Flowerpecker (Dicaeum cruentatum)
- Common Iora (Aegithina tiphia)
- Swinhoe's White-eye (Zosterops simplex)
- Collared Kingfisher (Todiramphus chloris)
- Red Junglefowl (Gallus gallus)
- Eurasian Tree Sparrow (Passer montanus)
- White-throated Kingfisher (Halcyon smyrnensis)
- Common Tailorbird (Orthotomus sutorius)
- Rock Pigeon (Columba livia)
- Olive-backed Sunbird (Cinnyris jugularis)
- Spotted Dove (Spilopelia chinensis)
- Brown-throated Sunbird (Anthreptes malacensis)
- Blue-tailed Bee-eater (Merops philippinus)
- Blue-throated Bee-eater (Merops viridis)
- Pink-necked Green Pigeon (Treron vernans)
- Sunda Pygmy Woodpecker (Yungipicus moluccensis)
- Oriental Pied Hornbill (Anthracoceros albirostris)
- Common Flameback (Dinopium javanense)
- Scaly-breasted Munia (Lonchura punctulata)
- Zebra Dove (Geopelia striata)
- House Crow (Corvus splendens)
Species Not Used
Out of the 30 Garden Birdwatch species, a few species couldn’t be retrieved from Xeno-Canto:
- Javan Myna (Acridotheres javanicus)
- Oriental Magpie-Robin (Copsychus saularis)
- Black-naped Oriole (Oriolus chinensis)
Some species are under extreme pressure due to trapping or harassment. The open availability of high-quality recordings of these species can make the problems even worse. For this reason, streaming and downloading of these recordings is disabled. (xeno-canto)
Evaluation: How Accurate Is BirdNET?
With coordinates set to Singapore (lat 1.35, lon 103.8), each file was scored based on the dominant call and filtered for confidence (>85%).
Show R code used for analysis
df |>
filter(Confidence > 0.85) |>
mutate(duration = `End Time (s)` - `Begin Time (s)`) |>
group_by(File, detected_com_name, original_com_name) |>
summarise(total_duration = sum(duration)) |>
slice_max(total_duration, n = 1) |>
ungroup() |>
mutate(isCorrect = if_else(detected_com_name == original_com_name, 1, 0)) |>
group_by(original_com_name) |>
summarise(
numOfRecordings = n(),
CorrectId = sum(isCorrect),
recall = round(CorrectId / numOfRecordings * 100, 0)
)
Results: Recall Rate by Species
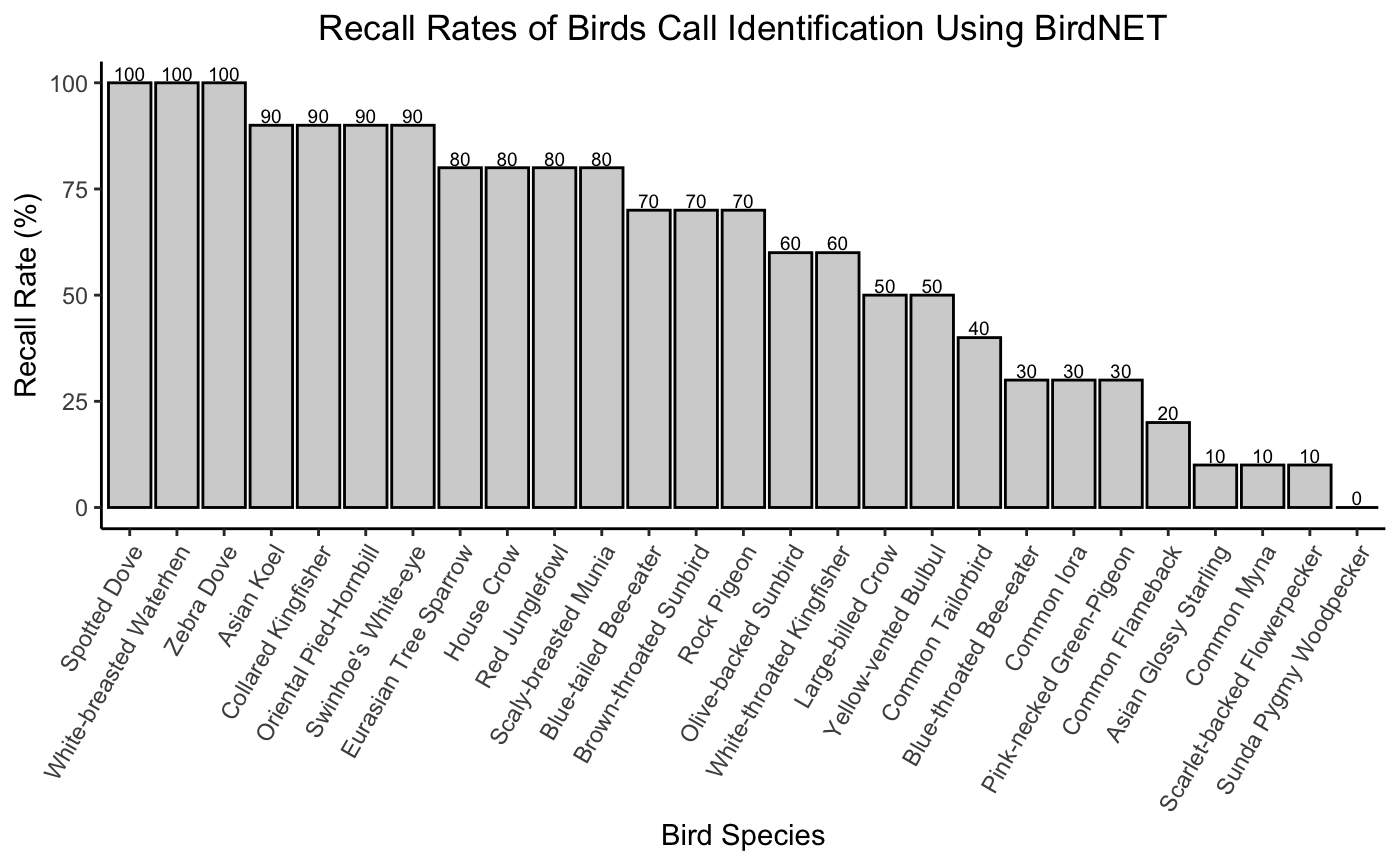
BirdNET excelled with species like the Spotted Dove and White-breasted Waterhen — both of which had a perfect 100% recall. These birds likely benefit from clear, recognizable calls that cut through ambient noise.
Middle performers, like the Eurasian Tree Sparrow and Olive-backed Sunbird, returned solid but imperfect results. These birds may have overlapping vocal traits with other species or simply appear less prominently in the model’s training data.
Then there were the challenges: species like the Sunda Pygmy Woodpecker, which scored a dismal 0%. Its rapid trilling — a sound not unlike the flutter of an insect wing or a rustling leaf — blends easily into the soundscape. Distinguishing it, even for a trained algorithm, proves difficult.
What Comes Next?
This experiment shows that BirdNET’s default model has real potential — and real limits. For species with distinctive, well-represented vocalizations, it's highly reliable. But for subtler, noisier, or less common birds, its accuracy drops.
Which brings us to the next phase. This trial was only the beginning. The next step is to fine-tune BirdNET’s model specifically for Singaporean birds — to build something more sensitive to local accents, habitat noise, and subtle song patterns.
Stay tuned. The jungle may be noisy, but we’re getting better at listening.
Stay Updated
Subscribe to our newsletter to receive new articles and updates directly in your inbox.